


The “archival turn” of the mid–20th century produced a conceptual shift away from the archive as a mute, transparent repository, toward viewing it as process or system. Michel Foucault, who substantially contributed to the theoretical framework of this turn, described the archive as “the general system of formation and transformation of statements,” an entity whose speech and silences delineate “the law of what can be said.”1 Concurrently in literary studies, an interest arose in recordings of poetry, largely owing to a literary critical re-evaluation of performance as essential to, even constitutive of, a poem’s meaning. The co-emergence of these two scholarly trends was no accident; in the literally enunicative audio recording, speech and silences are concretely rendered, allowing scholars to sound with greater precision the edges of the archives that contain them.
As collections of audio recordings enter the online environment and increasingly become viable resources for researchers, audio-textual relationships are foregrounded, on the one hand, by questions of design and functionality, and, on the other, by literary questions that interrogate a recording’s semantic and aesthetic value in relation to text-based analogues. These two sets of research questions are imbricated as researchers and designers contend with such questions as: how much text should be supplied and where should it appear in relation to the audio? How are digital audio files indexed, searched and organized using tools that are predominantly suited to text-based environments? How do content management systems and software mediate audio-textual relationships, and which allow for a dynamic experience with the audio artifact? The answers to these questions depend on who’s asking; digital audio archives are inflected by a shifting set of cultural and technological relations, and the Web’s rhizomatic structure always creates unforeseen and productively aberrant users and uses of technology. While digital archivists can imagine ideal users and tailor their sites’ interfaces with them in mind, opening archives to the online environment means allowing that environment to shape – and be shaped by – the unpredictable swerve of user communities.
Drawing from a survey of over 70 online digital audio archives, over half of which are of sounded poetry,2 I will propose three models of audio-textual relations, each using a paradigmatic example as a case study, that illustrate varied responses to the problem of integrating sound and text in an online environment. These models can be broadly termed modular (UbuWeb), situated (SpokenWeb) and constellatory (PennSound), and refer to both the particular archive’s organizational structure and its aesthetic ethos.3
Often born-digital and in an ongoing process of curation, the modular audio archive’s dominant aesthetic is bricolage. The audio artifact, in playback, is often divorced (in both streaming and downloaded formats) from any fixed textual components and there is no consistent format for the presentation of text and in playback. The situated archive focuses on a specific historical subject: author, location, community or event. Audio is tethered to the text, which provides extensive contextualizing and biographical information, transcripts and metadata. Where the situated archive’s textual mooring facilitates sustained, yet controlled engagement with the audio artifact, the modular archive’s textual vacuum favours user-directed listening and discovery. Finally, the constellatory archive makes meaning via the articulations between texts, interpretive communities, and systems of circulation. Its discrete, constitutive units – in this case, either “single” or “record”-length audio artifacts – are grouped into taxonomic categories: authors, reading series, playlists, events and anthologies. The effect of the constellatory archive is to reconcile the temporal paralysis of the audio artifact – the product of an irretrievable, singular event – with an ongoing, processual notion of history.
Modularity, situatedness and constellation are here presented as three emergent models of audio-textual relations; however, most audio archives employ a mix of aesthetic and technological strategies that puts them somewhere in between. There are certainly other lines along which to theorize the relationship of text to audio, such as content, genre or geographical location, though these remain outside the scope of the present article. At the paper’s conclusion, I outline four best practices for the design interface of digital audio archives. Briefly, these are: 1) employing content-based discovery tools; 2) making scalable networks; 3) offering transcripts and/or context-rich metadata; and 4) developing and integrating web-based digital audio workstations (hereafter, DAWs). These best practices result from my own extensive engagement with audio artifacts in an online environment over the course of my research as a graduate student in the humanities. I acknowledge that research activities vary between scholars and disciplines, and must emphasize that these suggestions are not meant to be a prescriptive approach to design; rather, they outline features that have been most helpful to me in my own work, and will hopefully serve as a platform to further assess the kind of work that humanities scholars do with digital audio archives, and in digital environments generally.
Founded in 1996, UbuWeb evolved from founder Kenneth Goldsmith’s personal collection of sound and concrete poetry into “a distribution center for hard-to-find, out-of-print and obscure materials, transferred digitally to the Web.”4 The site now offers more than two terabytes of audio in free, downloadable MP3 files, amounting to over 1300 hours of audio.5 Goldsmith touts the site as “the Robin Hood of the Avant-Garde,” designating acquisition and (re-)distribution as the primary functions of the archive.6 His essay, “The Bride Stripped Bare: Nude Media and the Dematerialization of Tony Curtis,” theorizes UbuWeb as a clearinghouse that embraces “the radical forms of distribution” inherent in the Web’s original technologies, ostensibly making accessibility the salient issue for contemporary archivists.7 However, if we’re persuaded by the LOCKSS mantra, “Lots of Copies Keep Stuff Safe,” then Goldsmith’s call for radical forms of distribution is equally a call for radical forms of preservation. Even if the site were to disappear overnight, as its manifesto suggests it one day might, the widespread circulation of its files within a user community radically increases the lifespan of its artifacts. This is the delicate balancing act of the modular archive: to preserve in spite of – and because of – the continual mutation of digital information. I will offer a detailed analysis of Ubu’s aesthetic and technological dimensions, in terms of text and audio, and their implications for the cultural reception of poetry.

Image 1: UbuWeb homepage screenshot, ca. 2013.
Coded by hand in HTML 1.0 using BBEdit, “the interface design of UbuWeb is intentionally modeled to emphasize [the] flat, cool, minimal qualities” of nonillusionist modern art: the captionless image of Samuel Beckett’s floating, disembodied head gazes down from the header onto a vast field of 8-point Veranda type against a plain white background.8 This textual landscape stretches on and on as the user scrolls down the page, never breaking the visual continuity of its three-column symmetry. The overwhelming presence of text negates meaning: in the absence of familiar typographical markers such as titles, taglines and captions, the user is unmoored and begins to scan. Ubu’s spatialized textual representation reminds us that in the digital age, most users acquire far more media than they could ever hope to consume. This textual excess-turned-vacuum also has a levelling effect by which no single medium or genre is privileged over another. The homepage is reminiscent of Ed Folsom’s generic grocery store landscape where “instead of the cacophony of 100 brands, each bearing its identifying colors and trademarks, each arguing for its uniqueness, we saw endless rows of plain white or yellow packaging with black letters: Laundry Detergent, Beef Stew, Pinto Beans, Beer.”9 Ubu’s design signals the dematerialized status of the digital files it archives: rather than visually representing the distinctness of each artifact, it instead points to the indiscriminate nature of new media, which codes all data, regardless of content, as integer sequences.

Image 2: UbuWeb sound page screenshot.
This non-hierarchical approach extends into UbuWeb’s organizational structure, where the 800+ entries on its intermediary “sound” page are listed alphabetically rather than categorically: authors, reading series, record and magazine titles, genres and poetic movements become equally viable structuring agents to access files. The reason for eschewing a taxonomical organization is that sound art defies classification. The sound page states: “as the practices of sound art continue to evolve, categories become increasingly irrelevant, a fact UbuWeb embraces.”10 By this logic, splitting the already fine hairs of generic and sub-generic classification might well result in each item requiring its own discrete category. While there is some cross-referencing between entries – for example, clicking on either “Allen Ginsberg” or the “Dial-a-Poem Index” will direct the user to the same recording of the poet’s 1972 performance of “Vajra Mantra” – the list lacks the consistency of a categorical system proper. As Ubu archivist Margaret Smith notes, “The implications of the existing organization are that it can be difficult to navigate the site or make connections between related resources. Because what is treated as an item varies, the descriptive metadata beyond the name of the creator is inconsistent.”11
Audio artifacts on Ubu are generally track-length, downloadable MP3 files that are accompanied by various textual snippets “ripped from the Web,” to use Goldsmith’s phrase.12 These range from biographical information, to album liner notes, to manifestos. The page for “? Concrete Poetry,” a 1970 exhibition at the Stedelijk Museum in Amsterdam, for example, is accompanied by a set of “Record Notes,” which offers a brief contextualizing paragraph for each track. Other pages use hyperlinks to point the user toward resources within and outside of UbuWeb; others still have no textual accompaniment and the only words on the page are in the links to the MP3s themselves. In contrast to the uniform intermediary pages used to navigate to the audio artifacts, the immediate textual environments that surround each one become surprisingly idiosyncratic, and an aesthetic of bricolage emerges through the site’s flat, minimal interface. Goldsmith’s observation that digital archiving requires an “obsessive stitching together of many small found pieces” reconciles a traditional conception of the archive with “the subjective handcrafting of an object into a unique and personal statement”; in short, the new archiving becomes a kind of folk art, stitching together an assemblage of social, material and historical relations to express “a larger community ethos.”13 However, while UbuWeb’s audio-textual bricolage reflects highly personal aesthetic and literary sensibilities, the onus is on the user to create a meaningful relationship between audio and text – a task that is heavily mediated by the site’s functionality.
There are four ways to play a track, each mediating audio-textual relations in a slightly different way. The first option is to play the file directly on the page in a modified version of the Javascript MP3 player, Playtagger. Clicking an icon next to the MP3 link plays the track, allowing the user to continue reading any text that accompanies the recording.
Image 3: Screenshot Playtagger on Ubuweb.
In this scenario, however, there are no playback controls for the user to manipulate. The track can be started or stopped, but not paused, rewound, or fast-forwarded. The lack of playback controls creates a less-than-ideal environment for sustained, in-depth engagement with audio artifacts; difficult sections that require multiple listenings cannot easily be repeated, and isolating stanzas or phrases in longer works is nearly impossible.
The second option uses audio.js, an HTML player UI with very basic features: a play/pause button, a track counter, a manipulable progress bar, and a click-to track listing. The player has better functionality than Playtagger, but is still difficult to control with precision – navigating a track using the progress bar is clunky in the absence of visual markers that signal duration, such as waveform visualizations, or hovering time code indicators. A third way to play files on UbuWeb is to click the link, which opens the MP3 file in the browser’s native HTML5 player. When one opens a link in Safari, for example, the browser automatically redirects to a new page so that the accompanying text on the UbuWeb page is no longer visible. The results vary depending on which browser one uses to open the file, but the important point is that while these native audio players offer a greater range of controls, the audio artifact is divorced from the textual matrix of the original page.

Image 4: Screenshot of Native HTML 5 Player in Safari.
The fourth way to play the MP3 is to download it by right-clicking the link and saving the file. From there it can be played on any number of audio players, added to playlists, emailed to friends, manipulated in DAWs, cut with other tracks, hacked up or remixed.
Ubu’s interface and functionality have significant implications for the listening conditions and cultural reception of sounded poetry. First, the song-length track abstracts the poem from the context of its original publication and from its performance histories, making it the primary unit for interpretation, rather than the collection, anthology or reading series. While the poem as a discrete unit is divorced from its historical context, researchers may discover previously unrecognized relationships as it comes into contact with other media. Second, as Jonathan Sterne has noted, MP3s pre-empt “the embodied and unconscious dimensions of human perception in the noisy, mixed-media environments of everyday life,” advancing casual modes and scenarios for listening to poetry, rather than sustained or focused ones.14 The extractability of the MP3 format extends sounded poetry into previously uncharted territory; freed from the confines of library walls, one could jog to Ernst Jandl or listen to Jaap Blonk in the bath, introducing a new sense of habitus to the disembodied audio recording. Finally, the ease with which MP3 files may be transferred, stored, duplicated and altered undermines the author’s position as the sole proprietor of his own work. If, as Sterne has argued, the MP3 is “a crystallized set of social and material relations,”15 then for Ubu these cohere into an ideological position on art, authorship and intellectual property. MP3s on Ubu are free in both senses – they cannot be bought and they are also, according to Goldsmith, “free or naked, stripped bare of the normative external signifiers that tend to give artwork as much meaning as the contents of the artwork itself.”16 Rather than treat this nudity as a crisis, however, UbuWeb embraces the creative and preservational potential that the MP3 affords; by refusing to make an evaluative distinction between original and copy, holding the mash-up to be as sacrosanct as the manuscript, Ubu enacts the avant-garde poetics of its holdings. The archive, then, self-consciously becomes a product of its own process: “Like files themselves, UbuWeb is becoming less stabilized in its identity as a center. Instead, we’re just another stopover point on the road toward instability and nudity.”17 The trend in all three cases is that it is the user, rather than the author, who defines the parameters for the reception of poetry.
Where UbuWeb is characterized by its sprawling, outward expansion in both content and scope,18 SpokenWeb focuses inward, tracing a network of historical, material and literary relations in a delineated subject. Developed by a team of designers, librarians and literary scholars at Concordia University in Montreal, SpokenWeb is an online audio archive that uses digitized recordings of a historical reading series as a case study. The Sir George Williams University Poetry Reading Series, which ran in Montreal from 1966 to 1974, involved more than sixty poets from important North American schools of poetry, including the Beats, Black Mountain Poets, and TISH, a Canadian poetry collective. Over its eight-year run, the series featured such notable poets as Margaret Atwood, Robert Creeley, Robert Duncan, Allen Ginsberg, Irving Layton and Al Purdy. The project’s mandate is to “create an interactive and nuanced tool that allows for deeper critical engagement with literary recordings” and to “eventually develop SpokenWeb into a refined tool that [can be shared] with other memory institutions who wish to make their digitized literary recordings available to scholars.”19
In contrast to UbuWeb’s flat, dematerialized design, SpokenWeb immediately signals its source material archive. The site’s banners show unique photographic details taken from the recordings’ reel-to-reel tape cases, complete with typewritten labels and penciled-in call numbers from a now-defunct cataloguing system. In calling attention to the normally invisible analog source, SpokenWeb’s design resists the self-effacing tendencies of digital technology. Martin Spinelli foregrounds the pervasive notion in digital culture that “the ‘best’ medium is the one that is ‘least there.’ Functionally and ironically, however, the less we hear [or see] the medium the more work it is doing to erase itself and, therefore, the more present it is.”20 Rather than reproducing the photographs of the tape cases as a documentary or skeuomorphic gesture, SpokenWeb instead transposes them into a familiar Web design component, the cover photo, rendering both the analog source and its digitization opaque.
Throughout the different stages of its development, SpokenWeb has been firmly rooted in a text-based environment. After digitization, the first method of processing the recordings was to transcribe all extrapoetic discourse including introductions, poets’ remarks and Q&A sessions. Using Transcriva, a proprietary transcription software suite, the transcripts were time-stamped and entered into a Word document along with biographical and bibliographical information and metadata, creating a 781-page catalogue. The SpokenWeb site was built using WordPress as its content management system, whose easy customization and interface facilitated the migration of the extensive text-based catalogue onto the Web. A custom post type plugin was used to organize the text into four tabs: “Meta,” containing fields such as catalogue number, speakers, venue, recording date, edits and duration; “Introduction,” an overview of the author’s biographical information and publication history; “Transcript and timestamps,” the transcribed extrapoetic speech and an index of time-stamped poem titles; and “Works cited,” which lists print sources that pertain to the reading.
In its organizational structure, SpokenWeb more closely resembles the digital collection as it is institutionally conceived: audio files can be browsed by year, alphabetically by author, or by call number. The recordings are not edited into song-length tracks, but are maintained in the full-length format of the event. This, coupled with the consistent description and classification of audio artifacts makes the reading series the user’s primary interpretive unit, rather than the individual poem. Common metadata fields allow for the comparative analysis of individual readings, and these give a sense of the reading series as a coherent whole. Jason Camlot, the project’s principal investigator, describes the poetry reading series as “a unique site from which to explore the implications of encounter between a geographically localized poetry culture and a diverse range of poetics as manifest in the individual performances of itinerant poetry readers.”21 SpokenWeb’s delineated historical and geographical territory allows researchers to map those encounters with depth and precision.
When the user selects a track on SpokenWeb, the audio opens in an embedded Soundcloud player at the top of the page, which scrolls down alongside with the text. Player features include volume control, track counter and most distinctively, a waveform visualization with click-to capabilities that tether the transcribed text to the audio.
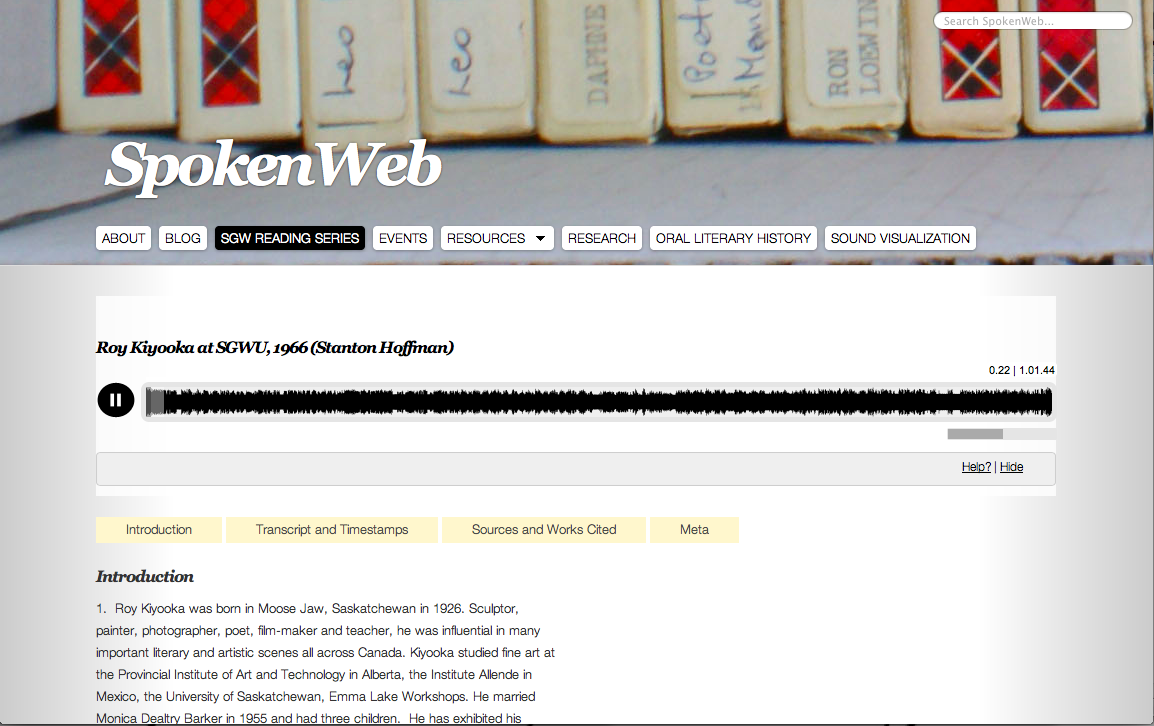
Image 5: Screenshot of SpokenWeb Audio Player.
Using jQuery, timestamps were converted into a whole number of seconds, which were then injected into the timestamp label as an ID attribute. When a user clicks to any point on the progress bar, the nearest timestamp is detected, and the page scrolls to the corresponding point in the transcription. The transcript is also highlighted based on the current position of the audio. Vice versa, clicking on any portion of the transcribed text will bring the user to that point in the audio. This feature creates an integrated audio-textual environment that favours in-depth, sustained engagement with the artifact: the user can search the transcript for repeated words or phrases that serve as interpretive touchstones; they can analyze the prosodic elements of a reading using the waveform alongside transcribed non-verbal cues (i.e. [laughter] or [applause]; perhaps most significantly, they can open up readings side-by-side to see, at a glance, a breakdown of their components.
SpokenWeb’s aesthetic and organizational dimensions are informed by a literary historical imperative that stems from the archive’s material core, and materiality in this case becomes a means of thinking beyond individual texts. Franco Moretti insists that “[t]exts are real objects – but not objects of knowledge. If we want to explain the laws of literary history, we must move to a formal plane that lies…below or above.”22 In the case of the audio literary recording, extrapoetic speech is the substrate below the event, and the reading series above it. SpokenWeb requires historicist methodologies to map the twinned narratives of the events and the media that documented them. The site’s oral history component, which offers audio interviews with organizers and participants of the Poetry Series, not only compensates for some of the informational gaps and silences in the recordings, it also reintroduces intentionality – what participants wanted to do and what they thought they were doing – as a relevant component of literary analysis. As a collection, these audio recordings provide critical information about authors’ relationships, the formation and interaction of poetic communities and, by extension, the narration of literary history through those communities. Like the meta-literary genres of letters and correspondence, audio recordings enable the convergence of agnostic text and author subjectivity.
UbuWeb and SpokenWeb can also be examined in relation to close reading and hyperreading, two distinct but equally viable modes of reading (or listening) discussed by N. Katherine Hayles in “How We Read: Close, Hyper, Machine.” Hayles notes that
close reading typically occurs in a mono-local context… Here the context is quite rich, including the entire text and other texts connected to it through networks of allusions, citations and iterative quotations. Hyperreading, by contrast, typically occurs in a multi-local context. Because many textual fragments are juxtaposed, context is truncated, often consisting of a single phrase or sentence.23
Close reading as methodology involves precise and detailed attention to language and rhetoric on a word-by-word level and works best within a limited field. Hyperreading is an important strategy for navigating information-intensive environments by enabling the quick discovery, assessment and juxtaposition of smaller bits of information. On one level, SpokenWeb is primarily concerned with facilitating close reading practices by employing transcriptions and visualizations. However, the ability to “zoom” to portions of audio using the site’s text-based search capabilities and timestamps promotes hyperreading strategies by allowing the user to quickly scan through lengthy transcripts to locate relevant information. UbuWeb, in contrast, creates a predominantly hyperreading environment by virtue of its expansive textual field and lack of finding aids. Its shorter segments of audio, meanwhile, create more manageable data sets in which to analyze prosodic pattern and formal structures more succinctly. As Hayles has convincingly argued, close and hyperreading need not be mutually opposed, but often work productively in tandem. A future consideration for both these archives is how to direct the generative possibilities of both modes of reading and allow the user to emphasize one or the other through customization, for example, by allowing transcripts to be hidden or visible, or by integrating a DAW to isolate shorter portions of audio within longer recordings.
The term “constellatory,” here used to describe a third model of audio-textual relations, emphasizes the generative possibilities of multiple ways of reading, navigating and seeing. I borrow the term from PennSound co-founder Charles Bernstein’s essay “Making Audio Visible: The Lessons of Visual Language for the Textualization of Sound,” in which he argues that
the availability of compressed sound files of individual poems, freely available on the internet, offers an intriguing and powerful alternative to the book format in collecting a poet’s work, and to anthology and magazine formats in organizing constellations of poems.24
Here, Bernstein articulates a philosophical position about the archive that is manifest in PennSound’s organizational structure – that literary artifacts, whether aural or textual, are semantically conditioned by their relationships to other things: texts, technologies, media, events. Constellation is an apt metaphor because it not only denotes a perimeter, a defined area of the celestial sphere, but also the patterns formed within it. Similarly, the digital archive, like the anthology or the magazine, is conceptualized as the container for and sum of its holdings, in which relational groupings are paramount. In the sound archive, however, these groups or patterns are not fixed, but are in constant flux – the same group of stars can form myriad meaningful patterns that are inflected by region, culture and history.
The recordings on PennSound can be accessed through multiple browsing paths, each conditioning an audiotext’s reception in a different way. A left-hand side bar allows the user to browse by author, reading series, anthology/collection/group and “single” – mostly one-poem tracks that are also listed alphabetically by author. Each provides an interpretive framework through which to structure the archive’s 8,000+ digital recordings. Browsing by author helps the user situate individual poems within the corpus of a poet’s work through the lens of that poet’s own self-presentation. Rae Armantrout’s work, for example, is organized on her author page along two axes. The first concerns her publication history, and orders readings chronologically from Veil: New and Selected Poems (Wesleyan, 2001), Up to Speed (Wesleyan, 2003), Next Life (Wesleyan, 2007) and her then-unpublished, Pulitzer prize-winning Versed (Wesleyan, 2010). This organization familiarizes the listener with Armantrout’s work and provides a historical trajectory of her career as a poet. The second axis is defined by reading events, for which Armantrout selected poems – as many as forty-four (Kelly Writers House, October 22, 2009) and as few as four (Kelly Writers House, March 22, 2013) – to represent her work before a specific audience at a specific time. The result is a generative tension between two historical situations of Armantrout’s work: the reified order of the books as she laid them out for publication, and the shifting, occasional re-constellation of those same works for live performance.
Like UbuWeb, the objects and texts surrounding the audio artifacts on PennSound are variable. Some author pages contain lengthy contextualizing notes about event structures and venues, production and recording; others contain author photos or embedded videos. Where PennSound’s audio-textual articulation differs from Ubu and SpokenWeb is in its frequent use of hyperlinks to create an intricate network of intra- and inter-site relationships. While UbuWeb also uses hyperlinks to point users to other resources, PennSound is distinguished by the density of its network: a sound page on Ubu has an average of 1.29 internal links and 0.9 external links, whereas PennSound author pages contain an average of 9.24 internal links and 3.04 external links.25 Armantrout’s page, for example, contains fifteen links to other PennSound pages, and seven links to external sites. Of the internal links, eight of them point to reading series pages, including the in-house, UPenn Close Listening, Kelly Writers House and Poem Talk Series, as well as other series whose audio is hosted on PennSound, such as AWP Offsite and Segue. Other internal links point to author pages (A.L. Nielsen, for example, who introduces Armantrout’s 2009 AWP reading) or flash-based, audio-text alignments that, like SpokenWeb, tether audio recordings of specific poems to their transcripts. Clicking on any one of these links opens other pages with equally dense referential networks in which authors, locations, dates, presses, radio stations, podcasts and reading series function as both nodes and edges. The user thus has the option to realize her own syntagmatic pathway through the database, creating the potential for serendipitous discovery. If this process gets too unwieldy, however, the ever-present list of organizational categories on the sidebar allows the user to revert to a controlled system at any time.
Kate Eichhorn usefully reminds us that “the author does not enjoy the same privileges in the archive that they do in the library” and PennSound reflects this authority-shift by offering event-based organizational categories in addition to author-based ones.26 Browsing by reading series creates constellations that group authors together in time and space. The 1978 calendar of the New York-based Ear Inn series featured paired readings by John Ashbery and Michael Lally, Jackson Mac Low and Rachelle Bijou, Bruce Andrews and Charles North, Susan Howe and James Sherry. The twenty-two poets who read in the series that year thus share an affinity outside the usual relational paradigms of literary tradition, influence and anthologization: their membership in the series not only connects them through a distinct locale, but also connects them across time to the hundreds of other poets who read in the series’ twenty-year run. Offering multiple, often concurrent, reading series as an interpretive framework creates a processual sense of temporality that countervails the fixity of the singular event. Listening to an author read the same poem at different events across time provides new foci for criticism that include the marginalized agents of event-based literary production: the audience, who equally produce meaning by entering into a reciprocal feedback loop with the performing author, and the space of the event itself, which provides stochastic intrusions and diversions from the event’s intended focus. Having multiple reading series grouped together on a single site opens up new avenues through which to assess what happens at poetry readings and how meaning is produced: applying distant reading methodologies to the data set of a given reading series could provide a quantitative analysis of what a poetry reading looks like. How long did readings last? How often did audience members laugh, interject or applaud? How many readers read on average per event, and what was the structure of the event – did they read sequentially, one after the other, or did they alternate? PennSound’s organization of readings by series facilitates both the synchronic, differential study of concurrent reading events, as well as the diachronic development of ongoing reading series over time.
Ultimately, PennSound’s organizational structure and aesthetic is undergirded by a pedagogical function that distinguishes it from both UbuWeb and SpokenWeb. In PennSound “Podcast #6,” Filreis explains how the archive’s vast collection of audio artifacts may help teachers provide a “line of continuity” (00:01:19) between contemporary poetic practices and prior movements and forms.27 The decision to encode all audio files in MP3 format embraces the same philosophy of radical distribution as UbuWeb. However, PennSound envisions its ideal end user as teachers and professors of poetry. This emphasis on pedagogy allows the archive’s artifacts to be freely distributed and reproduced on the web under the auspices of fair use and fair dealing. Filreis notes that all sound recordings appear with the copyright holders’ permission, and that there is a general consensus that “the increase in readers… far outweighs the potential for true piracy” (00:03:27).
The pedagogical activities that PennSound envisions for its files include: 1) the creation of comparative playlists “where differences and lineages both can be made apparent to the ear” (00:02:08); 2) emailing poems to students and colleagues in order to illustrate particular rhetorical or aesthetic strategies; 3) the integration of critical podcasts, such as Close Listening and PoemTalk into class material to contextualize poems in both their performed and printed versions. Organizationally, this pedagogical impetus is enacted through a variety of customizable options: multiple descriptive categories, proximate primary and critical sources, single-poem and reading-length files for the same reading event. A great degree of variability allows the user to choose what aspects of an audio recording are most relevant to her and her lesson plan. PennSound’s aesthetic ethos could perhaps be described as “anti-aesthetic” in a way that is far afield from the willfully minimalist design of UbuWeb. PennSound’s homepage contains only one image element that relates to its own branding: the aptly titled “PennSound_flat3.gif” that serves as its header. All other image files are third-party Web 2.0 logos (Google Plus, Facebook, RSS feed) or related to utility (play icon). Where UbuWeb uses distinct style sheets for its subsidiary pages (Sounds, Historical, Papers, Film & Video), PennSound uses only one main CSS. I would argue that this anti-aesthetic is informed by PennSound’s pedagogical intention, which values clarity, accessibility, transparency and sociality over unique self-representation.
I’ll conclude by suggesting four best practices for design and usability that focus on how audio and text might ideally be integrated in an online environment. These best practices take aspects from the three archival types I outline above, and aim to facilitate a broad spectrum of scholarly, pedagogical and creative activities.
1) Employing content-based discovery tools. The most user-friendly digital audio archives offer an array of customizable options for searching and browsing artifacts – functions that might broadly be termed “discovery tools.” Optimal discovery tools facilitate both targeted inquiry and serendipitous encounter. One way to strike this balance is to organize an archive’s contents into broader categories in addition to merely descriptive ones. For example, Lyrikline, a Berlin-based archive of sounded poetry, allows the user to search by spoken language, translation language, genres and aspects (i.e. experimental, concrete), issues (i.e. nature, life and relationships), and poetic forms and terms (i.e. ode, haiku). Its 968 authors can be searched alphabetically, by language or by country. This organization reflects a nuanced and intimate knowledge of the site’s content, which comprises sounded poetry in 63 different languages, from 101 countries.
Designers and project managers must give serious thought to the larger themes and trends that emerge in their archives’ contents. Of the three case studies detailed in this article, none offer thematic or generic categories through which to browse their content. For a situated archive like SpokenWeb, these categories might be easily implemented using WordPress’s tagging feature: a controlled keyword vocabulary could be used to generate consistent descriptions for poem types, features and themes. This work could be completed by a small group of participants (perhaps research assistants or students in a course), which would ensure standardization and consistency. Larger sites like UbuWeb and PennSound, whose corpuses are so large as to preclude a granular description from a single team, could make use of folksonomies and social tagging. The Naropa Poetics Archive at Archive.org has successfully implemented such a system, identifying themes within its collection such as New American Poetics, Buddhism, lyric poetry and the Black Mountain School. In order to ensure consistency, tagging options could be presented to users as a controlled vocabulary (perhaps in a drop-down menu), with the option of adding new categories approved by a moderator. PennSound and Ubu have large user communities that could help generate new constellations and modes of discovery within the archive.
2) Making scalable networks. Maximally usable archives also offer a flexible approach to scale, allowing users to “zoom in” on a single poem, phrase, or utterance, and “zoom out” to examine that same poem’s situation within an author’s oeuvre, a literary community, a national canon, or a transnational system of circulation. In this case, PennSound’s approach to the archive as constellation is ideal, allowing the user to easily transition between levels, and access contextualizing information within and outside the site. Importantly, and by virtue of its cogent taxonomical organization and clean design, it avoids the trap of “going down the rabbit hole” that transpires on other densely hyperlinked sites, like Wikipedia.
However, I would argue that constellatory sites could offer more types of inter-level linkage without sacrificing navigability. Such adaptations are crucial for scholars working on “connecting the dots” between people, institutions, and artifacts. My own work, for instance, involved tracking down individuals who could identify unknown speakers in recordings or explain how tapes recorded at the Vancouver Art Gallery in the 1960s ended up in the Concordia Archives (no donor information was available). These lateral connections are paramount for those working in literary history, and yet traditional methods of searching and browsing are often insufficient to the task. Other poets and scholars have been my primary resource for making these kinds of connections; however, this often involves lengthy email chains, fruitless searches and dead ends. As audio archives expand in scope and increase in number, there is immense potential to pool the knowledge and expertise of the people who use, contribute to, and maintain them. Digital archives could outline lateral linkages within their own contents, as well as point to content housed in other collections. For example, an archive could link a sounded poem to other instantiations of the same work on another site, or to other reading series that feature the same author or group of authors.
The Research-oriented Social Environment (“RoSE,” Alan Liu et al, UC Santa Barbara)28 and NewRadial (Jonathan Saklofske et al, Acadia University)29 offer two useful models for navigating scale. The former allows users to trace relations between texts, authors, and publishers in a network of nodes and edges; the latter presents the text on a sliding scale, using customizable views and networks to bring close reading environments into contact with big data visualizations. These tools do not create or alter primary content, but rather offer a way of organizing and managing relationships between the texts and agents of a literary field. Integrating one, or a series of, meta-level tools as a standardized feature among digital archives would be immensely helpful for scholars who work with collections, series and anthologies – those formal levels that lie above and below single authors and texts.
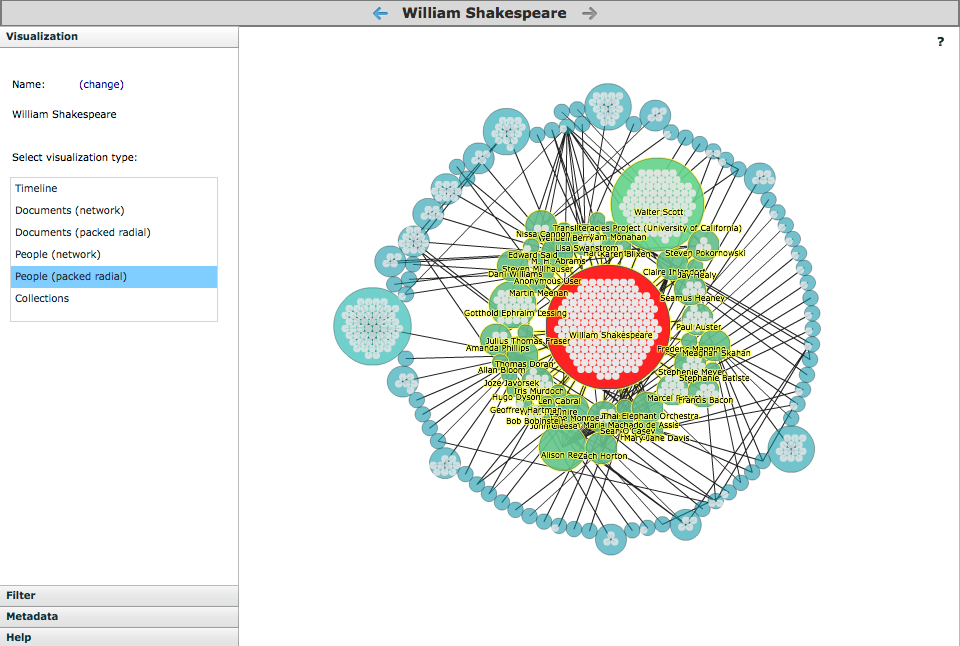
Image 6: Screenshot of RoSE interface.
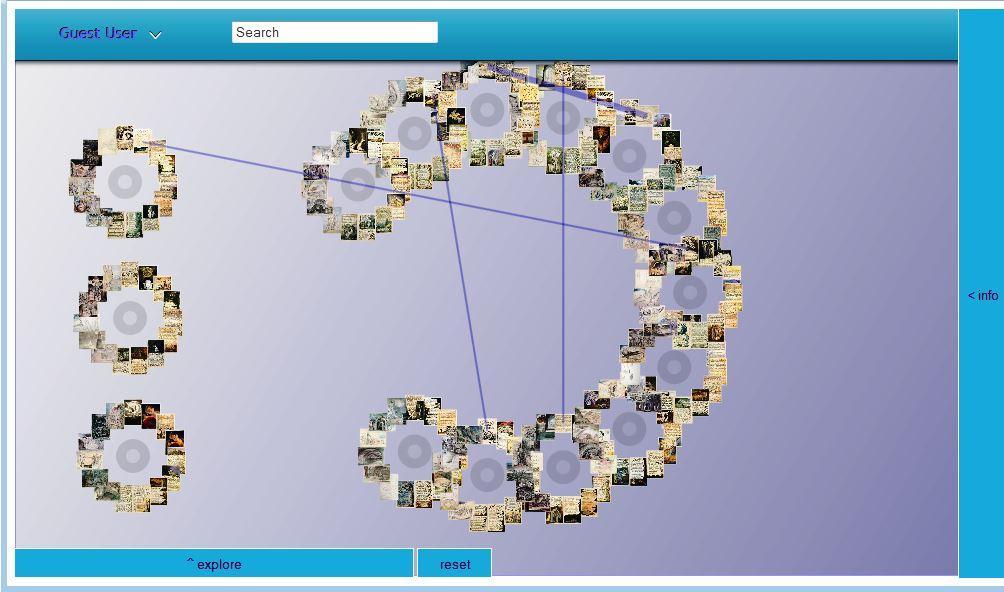
Image 7: Screenshot of NewRadial interface.
3) Offering transcripts and/or context-rich metadata. Beyond the initial step of locating an artifact, further consideration must be given to how users engage with the artifact itself – a process that, to a large degree, depends upon the (primarily text-based) scholarly apparatus that attends it. In my work with literary recordings, I have often found full-text transcripts to be the most useful tool for finding what I’m looking for. They have allowed me to identify and isolate topics of interest, and they have proved invaluable when sound quality is poor, or when a work contains a number of unfamiliar references. While it would be ideal to have transcripts accompany all digital audio artifacts, transcription is a time-consuming, labour-intensive and often costly process – something that is not feasible for larger collections of audio. In cases where transcripts cannot be produced, archival audio artifacts should ideally be accompanied by content descriptions that specify information such as genre, keywords, speakers, and themes.
Current digitization methods present untapped opportunities for generating comprehensive, context-rich metadata. For example, the files for my current project, the Roy Kiyooka Digital Audio Archive, were digitized in-house by undergraduate students in Simon Fraser University’s Digital Initiatives Lab.30 The students who digitized the artifacts generated basic metadata about the duration, accession number, and rate of transfer of the tapes, but supplied no information about the speakers, venues, events or literary content. The tapes in the Kiyooka collection embed the social dialogue of a specific community within a delimited historical period and, as such, require specialized knowledge to fill in this contextual metadata. However, since the tapes must be digitized in real-time, there is an ideal opportunity for an interdisciplinary collaboration between library sciences and literature students and faculty, who could generate context-rich metadata on a first pass if they were to work together. Not only would audio artifacts emerge with a useful set of identifying markers to be transferred online, but participants would emerge with an expanded skill set for describing both content and medium of the objects of their research. For artifacts that already have a digital life sans contextualizing support, I would again advocate for folksonomic classification, as well as user-generated annotation and transcription, methods that provide a basic framework for searching and browsing archival content.
4) Developing and integrating web-based DAWs. Sustained scholarly engagement with digital audio artifacts requires modes of listening that exceed the playback functionality of most web-based audio players. As Annie Murray and Jared Wiercinski note in their recent article, “A Design Methodology for Web Based Sound Archives,” while the search and collection of audio artifacts occurs primarily on digital archival sites, “most…scholarly activity likely takes place outside the site.”31 This means that the user has the cumbersome task of flipping between the site and her local audio player, and that the work she completes off-site will likely remain on her hard drive without being shared. The adoption of web-based DAWs to manipulate, edit and annotate audio helps make research more efficient, fluidly integrating audio files into text-based scholarly apparatuses (such as transcripts, timelines, bibliographies, etc.), and providing a forum for multiple users to engage in new ways with the same artifacts.
DAWs would ideally offer the following features: 1) variable playback speed to facilitate transcription; 2) waveform and pitch curve visualizations to help isolate portions of speech, prosodic patterns and sections within longer recordings; 3) a “zoom in” function that allows users to isolate and loop shorter portions of speech (i.e. when attempting to decipher difficult portions of audio); 4) a comparison tool that allows two or more recordings to be loaded as tracks and played simultaneously; 5) haptic playback features that tether movements (mouse wheel or touch screen) to fast-forwarding and rewinding; 6) an export function that extracts a selected portion of a recording as an MP3 or WAV file; and 7) temporal annotation tools, where users can insert time-stamped comments onto the waveform itself.
Unfortunately, there are currently no out-of-the-box audio players that sport all of these features, so one’s options are limited to custom-code or compromise. Soundcloud offers an excellent, free, customizable player that is compatible with several of the most popular content management systems (including WordPress and Drupal). It offers many of the features listed above, such as waveform visualizations and temporal annotation. Additionally, its active developer community is responsive to user needs; as more spoken word archives call for specialized tools, developers are likely to rise to the challenge of crafting functional, embeddable DAWs.
User needs and behaviours shift rapidly in a digital climate, meaning that web-based archives must adapt quickly to stay visible and relevant. Since the first version of this article, both PennSound and UbuWeb have made significant changes to their sites’ GUIs by incorporating anchored audio players with greater playback functionalities (audio.js and Yahoo! respectively). To me, these changes signal the fact that audio archives are beginning to conceive of themselves not only as repositories for access but, increasingly, as digital environments in which users encounter, work and play with audio. As such, digital design should emphasize flexibility, variability, and customization to accommodate a broad spectrum of research activities. Each archival type – modular, situated and constellatory – facilitates different modes of discovery, and optimal design will allow users to select aspects from all three. The benefit of creating online spaces in which researchers conduct their work is that, much like the events that many audio artifacts document, this work can be shared between users, and account for a broader range of perspectives and positions. There is always more than one way to map a territory, and offering flexible coordinates offers the potential to continually generate new pathways, destinations and discoveries.
Michel Foucault, The Archaeology of Knowledge, trans. A.M. Sheridan (New York: Pantheon Books, 1972), 129. ↩
Fong, Deanna, and Celyn Harding-Jones, Annie Murray, Jared Wiercinski. “Audio Archives.” SpokenWeb. Concordia University. http://spokenweb.concordia.ca/audio-archives. ↩
I acknowledge that the term “modular” carries significant back-end design connotations, and if I were to write a paper with Web development as its focus, the two terms “situated” and “modular” might there be reversed: Ubu is coded in-house, by hand, its development is therefore mono-local or “situated,” whereas SpokenWeb uses a variety of out-of-the-box tools and software, such as Soundcloud and WordPress. ↩
“UbuWeb FAQ,” http://www.ubu.com/resources/faq.html. ↩
An estimation based on the average MP3 file size of 1.1MB per minute. ↩
Kenneth Goldsmith, “UbuWeb Manifesto,” UbuWeb. http://www.ubu.com/resources/faq.html ↩
Kenneth Goldsmith,“The Bride Stripped Bare: Nude Media and The Dematerialization of Tony Curtis,” New Media Poetics: Contexts, Technotexts, and Theories (2006): 49. ↩
Goldsmith, “The Bride Stripped Bare,” 51. ↩
Ed Folsom, “Database as Genre: The Epic Transformation of Archives,” PMLA 122.5 (2007): 1571. ↩
“About UbuWeb Sound,” UbuWeb. http://www.ubu.com/sound/ ↩
Margaret Smith, “Structure and Classification: Archiving Ubu,” http://archivingubu.wordpress.com. ↩
Kenneth Goldsmith, email message to author, May 21, 2013. ↩
Kenneth Goldsmith, “Archiving is the New Folk Art,” Harriet: A Poetry Blog, The Poetry Foundation (2011), http://www.poetryfoundation.org/harriet/2011/04/archiving-is-the-new-folk-art/ ↩
Jonathan Sterne, “The MP3 as cultural artefact,” New Media & Society 8.5 (2006), 826. doi: 10.1177/1461444806067737 ↩
Sterne, “MP3,” 826. ↩
Goldsmith, “The Bride Stripped Bare,” 52. ↩
Ibid, 62. ↩
Ubu continues to acquire contributions via donation and by digitizing rare, out-of-print, or obscure materials. ↩
“About SpokenWeb,” http://spokenweb.concordia.ca. ↩
Martin Spinelli, “Electric Line: The Poetics of Digital Audio Editing,” New Media Poetics: Contexts, Technotexts, and Theories (Cambridge, Mass.: MIT Press, 2006), 104. ↩
Jason Camlot, “The Sound of Canadian Modernisms: The Sir George Williams University Poetry Series, 1966–74,” Journal of Canadian Studies/Revue d’études canadiennes 46, no. 3 (2012): 29. ↩
Franco Moretti, “The Slaughterhouse of Literature,” MLQ 61.1 (March 2000), 217. http://muse.jhu.edu.proxy.lib.sfu.ca/journals/modern_language_quarterly/v061/61.1moretti.html ↩
N. Katherine Hayles, “How We Read: Close, Hyper, Machine,” ADE Bulletin 150 (2010): 74. http://mmize.digitalodu.com/courses/wp-content/uploads/2013/05/Hayles.pdf ↩
Charles Bernstein, “Making Audio Visible: the Lessons of Visual Language for the Textualization of Sound, “ Textual Practice 23 (2009): 964–5. doi: 10.1080/09502360903361543. ↩
This average is based on a sample of 70 sound pages from each site, physically counted between January 5, 2014 and January 11, 2014, using the online Link Counter tool (http://linkcounter.submitexpress.com). Please note that static content, such as navigational links, which appear on the sidebar and at the footer of the page, and links to MP3 files themselves, were not counted in this survey. Internal links are defined as those that remain rooted in the general domain names http://www.ubuweb.com and http://writing.penn.edu. ↩
Kate Eichhorn, “Past Performance, Present Dilemma: A Poetics of Archiving Sound,” Mosaic 42 (2009): 183–198. http://search.proquest.com.proxy.lib.sfu.ca/docview/205371919. ↩
Filreis, Al. “Podcast #6,” PennSound, http://media.sas.upenn.edu/Pennsound/podcasts/PennSound-Podcast_06_pennsound-overview.mp3 ↩
Research Oriented Social Environment, accessed October 9, 2014, http://rose.english.ucsb.edu/ ↩
NewRadial, accessed October 9, 2014, http://inke.acadiau.ca/newradial/ ↩
The Roy Kiyooka Audio Archive is a collection of 404 recordings made between 1963 and 1988 housed at Simon Fraser’s W.A.C. Bennett Special Collections. Inscribed on a variety of formats, including cassettes, reel-to-reel tapes and mini-cassettes, these recordings offer a unique individual and collective autobiographical perspective of one of Canada’s foremost artistic and literary figures, creating a rich soundscape of poetry readings, conversations, musical and field recordings. http://roykiyookaaudioarchive.wordpress.com ↩
Annie Murray and Jared Wiercinski, “A Design Methodology for Web Based Sound Archives,” DHQ: Digital Humanities Quarterly 8 (2014): par.5. http://www.digitalhumanities.org/dhq/vol/8/2/000173/000173.html ↩
Article: Creative Commons Attribution-NonCommercial-ShareAlike 3.0 Unported License.