


In the early 1990s, a hot debate reigned over machine translation (MT) research, divided quite sharply and dramatically along methodological and philosophical lines. On one side were the so-called rationalists, who applied rule-based approaches derived from linguistic theories to computer translation. On the other were the so-called empiricists, a new group identified with the brute processing approach pioneered at IBM Yorktown Heights, which involved the statistical modeling of large datasets of translated material. At a 1992 MT conference, researchers staged a “medieval disputation” between the two camps; at stake was the future itinerary for MT. Now when this period is recalled, the story is one of simple victory for the empiricists over the rationalists, of new and improved statistical methods over passé rule-based techniques. The problem with this narrative is not only that it reinforces an untenably stark binary between “top-down” and “bottom-up” approaches to MT and the kinds of knowledge cooked into their designs, but that it neglects the human in MT, both at the development stage, and at the user end.
The analysis that follows unsettles this narrative in two ways. First, it revisits the disputation itself, and tends to arguments that show the binary to be much less stark. Second, it discovers – seemingly beyond the framing terms of the dispute – an expectation that end-users would train themselves to work with the “crummy” output generated by statistical systems. What’s more, this expectation was baked into then-emerging evaluations schema that compared machines with machines instead of with human translators and helped guarantee these systems to be successful ones. My general intention is to emphasize that the techniques of “machine” translation, like those of any translational activity, are sociotechnical processes.1 With respect to statistical machine translation specifically, I show that its success was not a singular and inevitable outcome of its technical design alone, but was further socially configured insofar as human learning and labour ultimately underwrote its functionality. My aim is not to naively discount the success or scope of probabilistic methods – they won the day – but to contemplate the management of alternative or multiple genealogies for translation automation at the moment of their imagined and proposed transformation, as a form of institutional and laboratory critique. When empiricism won, what, if anything, was lost?
This investigation shares the media studies concern for digital infrastructure, standards, and protocols, as well as formats – translation’s method is also its textual output – and is further inspired by the recent call by historians of technology to attend to maintenance over or alongside innovation.2 The aim is not only to mount a challenge against technological solutionism, but to shed light on the tendency to prioritize the new over what already works; as scholars Andrew Russell and Lee Vinsel put it, to “scrap existing reality and start over again from scratch.” While the new and innovative is foregrounded and funded, less attention is paid to the “mundane labour” that is critical for the efficient functioning of systems and infrastructures. Translation is an essential part of communications networks, as a set of techniques and workflows that realize the production, distribution and consumption of text (linguistic) products. And like much infrastructure, when translation works, it often goes unnoticed. That MT inscribes new labour, training, and publication regimes into its operation makes it comparable to other investigations into unrecognized or under-theorized inscriptive labour, and brings needed contour to translation as a media operation and media form.3
In this vein, it’s significant that MT is often held up – despite its consistently capricious yield4 – as the most basic example of Artificial Intelligence; their conceptions and fortunes are linked. In a broader sense, then, it’s worth exploring connections between the ways MT software was envisioned and designed to perform “automatically,” and computational infrastructures that reinforce, as Rita Raley has proposed, “the techno-linguistic consensus.”5 It seems this consensus was, at one time at least, the product of dissensus. What helped developers agree to agree, and subjected those thereafter – from industry partners to end users – to its logic? How is the techno-linguistic mandate operationalized for this “we”? How are we enlisted in the task? Do we even use MT? Does it even work? Should it? Such questions are worth asking, especially now, as we witness yet another methodological watershed in the shift from statistical techniques to neural networks; demonstrating that learning – by people – was imagined as a function and outcome of this past success helps shine critical light onto that set of techniques and contexts now often quite casually referred to as “machine learning.”
Going Medieval: 1992 Conference and Disputation
IBM’s statistical method and results were first presented at the COLING (computational linguistics) conference in 1988, and published in Computational Linguistics in 1990.6 In brief, IBM had used information theory to model translation from parallel text, in their case, hypothesizing that English traveled through a noisy communications channel that garbled it into French. Proposing that this channel could be expressed mathematically, IBM rearticulated the translation process as one void of understanding, and reduced translation to a “Fundamental Equation of Machine Translation.”7
Two years later in Montreal, the biannual “TMI” conference series on “Theoretical and Methodological Issues in MT” devoted itself to the methodological divergence, subtitling the event like a boxing match: “Empiricist versus Rationalist Methods in MT.”8 Pierre Isabelle and Elliot Macklovitch, Canadian organizers of the event who’d worked in MT since the 1970s, sensed the pendulum swinging fast towards the statistical methods, and shared in the growing consensus that the data-driven methods were worth pursuing. Pinning the meeting to the controversy would serve as a public demonstration of the shift in favour towards the data crunchers. Many researchers, for instance, were already working out how to apply hybrid methods. A lighthearted “medieval disputation” would close out the event as the conference’s concluding panel, with heckling and discourtesy encouraged. The twist of the debate was that invited speakers for the opposing sides – “for rationalism,” “for empiricism” – were asked to make their cases for the language engineering paradigms they themselves did not practice.9
At the broadest level, the thematic opposition showcased epistemological theories, the matter of how we come to have knowledge. An empiricist position would hold that knowledge can only be acquired through sense experience, while the rationalist would assert that knowledge can be innate, reasoned, or acquired through logic. The terms were used narrowly in MT, to characterize different ways of modeling translation using computers. The IBM empiricists looked at large bilingual corpuses as evidence of translation and used their equation as a “key” for modeling it. While the IBM team acknowledged that modeling translation as an equation was “fanciful,” it unsettled the “intuitive appeal to the idea that a translator proceeds by first understanding the French, and then expressing in English the meaning that he has thus grasped.”10 The rationalists, influenced by linguistic theories, tried to devise a system (ideally, a minimalist one) of steps, rules and principles that would describe, perform, and perhaps help to explain how translation happens at the linguistic level.
The conference’s keynote addresses set the stage for the disputation to come. The first paper, given by Robert Mercer of IBM, was titled “Rationalist MT: another cargo cult or just plain snake oil?” Mercer characterized the rationalist researchers as “deceived by their own theories” and distracted by philosophical issues, and of rationalist research as “wishful thinking.”11 In contrast, empiricist research cared about “whether something works or not.”12 For the rationalists, Yorick Wilks gave a keynote called “Stone Soup and the French Room,” referencing Searle’s Chinese Room thought experiment (IBM’s system worked into French) and the parable of the traveler who claimed to be able to make soup from a stone.13 Searle’s experiment claimed that language could be processed meaningfully without the processor (human or machine) “knowing” that language, as long as instructions for symbol manipulation were provided. But like the traveling chef, whose stone-soup preparation always involved borrowing just a pinch of this and a just a dash of that, Wilks contended that IBM, too, would ultimately need additional ingredients – linguistic insights – to better its admittedly impressive results.
Of course, all the researchers considered their work to be empirical, that is, based in fact and scientifically sound. While the nomenclature somewhat misrepresented the divide, and was contested by some participants,14 it helped mark dissent as old-fashioned and orthodox, and dissenters as blind or resistant to forward strides. The IBM team played up the contrast even further in their TMI paper, rendering parts of their write-up in a dialogue format between Simplicio and Salviati, as in Galileo Galilei’s 1632 Dialogue Concerning the Two Chief World Systems, which marked the shift from Scholastic theological dogma to Age of Reason empiricism.15
In the IBM paper, Simplicio and Salviati engaged in a surface reading exercise meant to undo the “intimate familiarity with reading and writing that we all share.”16 Computers didn’t process words, as people did, but as strings of characters. While spaces and punctuation were useful in navigating “the passage from a string of characters to a string of words,” they also noticed that “at intervals it becomes tortuous”17:

Fig. 1. Excerpt (p. 88) from Brown et al, “Analysis, statistical transfer, and synthesis in machine translation,” presented at TMI-92.
The solution for IBM was to “encode many of these decisions,”18 to normalize what would appear to computers as writing irregularities or inconsistencies, and to humans as unnoticed (since learned, internalized) writing conventions. These included, for instance, identifying compound nouns, whether they were hyphenated or separated by a space, discerning the difference between capitalized and uncapitalized words, identifying contractions, names and abbreviated titles. Identifying and regulating these anomalies and “exceptions” to make sense of their strings involved introducing top-down encoding decisions (even if the means of discovering and deciding them was done algorithmically, not manually), indeed quite similar to the rationalists. The IBM paper focused the rest of the paper on outlining various sentence transformations their updated system executed in order to make French and English sentences “more similar to one another,” many of which involved familiar grammatical rules (such as question inversion), which improved the functioning of their statistical model. This analysis was performed by a finite-state machine, to which, the authors acknowledged, no language was reducible; there would, therefore, be mistakes. “While this is regrettable,” IBM wrote, “we take a purely pragmatic attitude toward these errors: if the performance of the system improves when we use a transformation, then the transformation is good, otherwise it is bad.”19
Such tweaks for perfecting and improving base results carried with them the likelihood of a hybrid methodological future. Moving forward, it might be hard for IBM to claim that its system had no understanding; some knowledge was seemingly baked in, whether accounted for by linguistic theory or “intuitive” text-formatting conventions.20 When it came time for the “medieval disputation,” however, instead of looking at how the methodological differences affected the specifics of production and programming, or implied priorities and trade-offs arising from concrete end-uses, the debaters floated loftier concepts: human language competence and the mysteries of its acquisition, the nature of the parallel corpus as a model of translation expertise, and the relationship of human linguistic knowledge to IBM’s “agnostic” data processing. Arguments on both sides veered towards philosophical matters – “distractions,” as Mercer had termed them, in his “snake oil or cargo cult” keynote.
An audio recording was made of the disputation, which moderator Margaret King declared open as follows21 :
Ladies and gentlemen, will you take your seats please for your trip back through time. The next event of this conference is a medieval debate.
The debate format was suggestive; in the medieval university, the formalized rhetorical techniques of disputation were taught, practiced, and applied predominantly to theological topics. As in those centuries-old contests, the aim of the TMI debate was to refine and reiterate the tenets of dogma, while winning converts to one’s side. It was a fitting frame: the IBM team were not just methodological heretics, but real outsiders – well-versed in natural language processing (NLP) through their work on speech recognition, but newcomers to the specific problematics of translation. Making the debate “medieval” brought with it other presumptions about doctrinal study and scientific experimentation, a contrast between the lofty, theoretical, hands-off approach of the research university versus the grittier and presumably grounded methods of the corporate research lab.
Graeme Hirst, who took the dais on behalf of empiricism, alluded to trade-offs and mixed methodologies: a middle road between the rationalist and empiricist positions.22 Such hybrids, Hirst kidded, were “pretty wimpy” – “you try to maximize your chances of being up to half right at the price of being definitely at least half wrong.” To make the case for empiricism, Hirst followed a familiar tactic, disparaging rationalism’s dubious relationship to science. “It’s been shown over and over again that the linguistic intuitions on which rationalism are based are inherently flaky and completely unreliable.” Even the rationalist claim that language worked like mathematics, which one might expect would raise its scientific profile, wasn’t enough to recuperate it. Hirst reminded the audience of the space between mathematical statements and the physical world, and it was professional translators who commanded the linguistic space between “the nasty, messy stuff that you get in the real world and the idealizations that the rationalists would have us believe in.” Theoretical linguistics, on which rationalist MT was based, failed to provide the right kinds of insights, such as “direct function or structure in the human sentence processor or the human language processor.”23 The pro-empiricist takeaway was that linguistic bosh was getting in the way of real computer work. By 1992, this was already a common tactic in speech and language processing circles, the animosity for linguists summed up in a frequently repeated phrase delivered several years earlier by Fred Jelinek, head of IBM’s speech recognition and later MT projects: “Every time I fire a linguist, the performance of the speech recognizer goes up.”24
Though Hirst placed linguistics sympathizers on the far end of the rationalist scale, he didn’t see the IBM approach as its polar empiricist opposite. Instead, Hirst wavered from his strong pro-empiricist stance and carved out a third space for practitioners who believed their MT work modeled a skilled human activity and produced insights about that activity, without reducing that activity to mathematical mappings and predictions based entirely on text output. “If we want to build computational translators,” Hirst proposed, “what we need to do is study translators, and not translations.” Work was already happening in this vein, and Hirst pointed to Example-Based Machine Translation (EBMT), which used a neural network and connectionist matching. Instead of modeling just one of supposedly “innate” language or “worldly” texts, EBMT tried to emulate the accumulation of learned examples as translators would as they gained experience – not as childhood language acquirers, but throughout their professional careers. Hirst’s arguments revealed flaws in both approaches, and IBM was ultimately – and jokingly – accused of developing a product with foundations as imaginary as the rationalists; this was “pixie dust,” “found to translate sentences of up to five words long with 60% accuracy.”
Ron Kaplan (now VP of Amazon), also speaking on behalf of Empiricism, veered away from the nuts and bolts of everyday translation work to contemplate instead the “difference in scale between the complexity of language and the reasoning power of the human brain.” Kaplan concurred with the rationalist position regarding the paradox of seemingly knowing so well something as “big” and “impossible” as language – “the thing we can do and not know.” Instead of appreciating that immensity and discovering ways of working with it, rationalists were stuck in the aim of describing it, trying to devise and “fit” a universal theory that left them dealing with “little isolated atomic units.” As a result, Kaplan lamented, rationalist MT programs were fragile, they couldn’t handle “the continuous sweep of the real world,” they didn’t permit “graceful degradation,” and instead produced “catastrophes.” While empiricism represented a needed escape, the opening of a “jail door,” it, too, had its problems. As Kaplan noted, lost context through abstraction was an affliction faced by both groups. “Whatever linguistic thing you’re doing,” Kaplan admitted, “however you’ve abstracted it, you’ve lost something that’s going to be crucial for some aspect of translation.” The empiricists would take things further than the rationalists due to exponentially increasing computing power, of “computons in data.”
For Kenneth Church (then of AT&T), speaking in support or rationalism, the confrontation boiled down to cost and quality, with statistics providing the cheaper route: “With friends like statistics, who needs linguistics?” Church continued:
Numbers can be cheaper, yes, they’re offering you a free lunch. But that doesn’t make the lunch any good. There are easy answers which don’t cost too much. If you want answers requiring thought, you have to pay. I’m sorry, but we’re not offering you a free lunch, they are. And their wrong answers are quite cheap.
Instead of “preaching to the choir” of rationalist sympathizers (this was the “conservative party position”), Church discredited the IBM (minority) view by reiterating its flaws. Empiricism was mysticism, pixie dust, numerology! It was irrational, but claimed to be “self-organizing” (“right, right,” Church added, sarcastically). The heart of the problem was that “the numbers aren’t necessarily more trustworthy than the truth.” The practical stake of the methodological shift was that low-cost methods delivered uncertain results in local implementations, which was where translations were ultimately evaluated, by readers. While the rationalists may have been rightfully suspicious of a statistics-only approach, some were perhaps too transfixed by a belief that translation could be theorized in a single way, as a generalized linguistic operation.
In the ensuing discussion, Hirst pressed Kaplan on the black-boxedness of the empirical approach and the problem of evaluation: “if you haven’t got the ability to comprehend this immensely complicated structure, how are you going to assess whether you’ve succeeded?” In response, Kaplan insisted on the futility of the linguistic-oriented approach because it would never be able to master the whole: “This whole sort of ontology that says that you have to understand all this stuff that’s on the inside, that you’ve got to kind of chart it out and connect it. I mean, that’s crazy. No one’s ever going to be able to do that.” The empirical approach “worked” because it could be compared with human performance:
you need […] to look at the behaviour of the system that you’ve built, look at the behaviour of people, and compare them. It’s an empirical question. That’s why this method works, is because there is a way of knowing when you’re right and wrong. […] When we build the models, we’ll test them. We’ll do an evaluation, and we’ll know whether or not they can perform language tasks. It’s not a hard problem, it’s an empirical question.
The problem, of course, was that for the empiricist position to “work,” it needed to strive for a similar universalism; instead of a general theory of language, it needed a database of everything.
Innateness of Format
Speaking on behalf of rationalism, Geoffrey Sampson added nuance to the terms of the debate by pointing out that rationalism vs. empiricism implied both “a cognitive thesis, about human nature,” and “an engineering view […] about techniques to be applied in knowledge engineering applications,” such as MT. The difference was bound up with the cognitive thesis; either you were cognitively a rationalist, and supported the notion of linguistic universals and the innateness hypothesis, or you were cognitively an empiricist and against these ideas. The creation of working MT systems, however, was an engineering problem for researchers on both sides, and Sampson found fault with the empiricist approach for denying the researcher any determining role in the process, by “simply by leaving the systems to work it all out for themselves.” People already knew things about how language worked, and should have a hand in telling computers what to do with it. This would be preferable to “just throwing the Canadian Hansard at them and hoping that they’ll discover that where it says “marquées d’un astérisque” in the French text, there usually seems to be the word “starred” around somewhere in the English text.” The “Hansard” was the corpus that IBM had used to model its statistical method – a transcribed bilingual text of Canadian parliamentary proceedings, a record that was translated, published and distributed every single day when parliament was in session.25 Wilks’s had mockingly called the Hansard “the Rosetta Stone, one might say, of modern MT.”26
“From an initial situation in which each French word is equally probable as a translation of starred,” explained IBM, “we have arrived, through training, at a situation where it is possible to connect starred to just the right string of four words”: “marquées de un astérisque.”27 We can view the original examples in the printed Hansard:

Fig. 3

Figs. 3 and 4. The original sentences are in the bottom-most outlined boxes of each of the French (green) and English (red) versions, beginning “M. Reid” and “Mr. Reid,” respectively.
IBM had discussed the last part of this sentence as well, and pointed out that a twelve-word English clause (I now have the answer and will give it to the House) corresponded to a seven-word phrase in French (je donnerai la réponse à la Chambre). “Translations […] as far as this from the literal are rather more the rule than the exception in our training data,” IBM noted, remaining vague on the question of whether “literalness” was a function of meaning or of word count.28 The empiricist advantage on the methods battlefield was to refuse to be surprised. While “one might cavil at the connection of la réponse to the answer rather than to it,” IBM pointed out, alluding to its grammar-fixated opponents, “We do not.”29
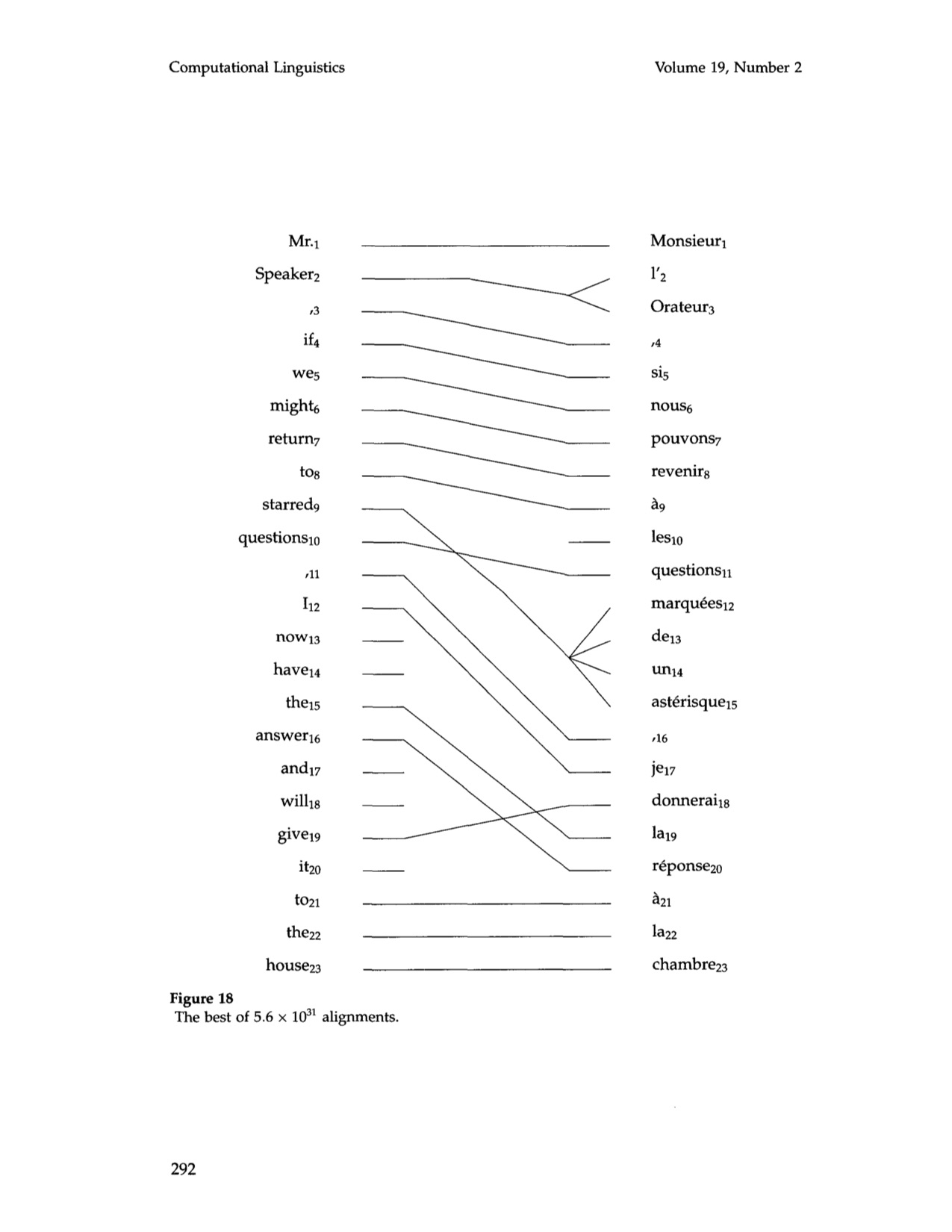
Fig. 4. Diagram from Brown et al (1993), depicting a “best” sentence alignment and a “non-literal” translation.
Sampson’s point was not that translators already knew these things; the objective for rationalist MT researchers, too, was to transfer that knowledge to computers. Rather, his defense of rationalism centred on who was teaching who or what to do what. With the IBM approach, researchers were asked to suppress their own knowledge of existing correlations – between stars and asterisks, between long clauses and short ones, between seemingly word-for-word and seemingly “non-literal” translations – and then admit they’d been “taught to our great surprise that these two phrases go together.” IBM acknowledged that certain correlations “shout from the data,” adding that “any method that is not stone deaf will hear them.” Other correlations, however, “speak in a softer voice: to hear them clearly, we must model the translation process.”30
Given this recognition of more and less obvious correlations, what’s especially interesting about the “starred” example is how specific it is to the procedural and documentary flow that created the Hansard. If we look again at the French Hansard page from which IBM’s example was drawn (May 6, 1974), we see that it features the word “astérisque” three times – twice as part of a parliamentarian’s verbatim speech, and a third time in a fixed sub-heading, itself a mechanism of parliamentary procedure that helped readers navigate the Hansard record itself.31 The third instance didn’t even derive from “starred questions,” as might have “shouted from the data,” but from the English word “asterisk.” The point is that MT developers of either bent had to contend with the yawning gap between the pro forma nature of the sub-heading as specific to the Hansard, and the expectation that a database or a linguistic theory could serve as a stand-in for English-French “translation” in most any context.
While IBM used these examples to underscore a surprisingly regularity, a close reading reveals two errors and, in them, the humans doing the work; a missing plural “s” (Question answered orally are indicated by an asterisk) and a numerical misprint (“Starred question No. 63” becomes “la question no. 43 marquée d’un astérisque.”) Errors are a natural occurrence in “human translation” as a step in a print production chain; this is why translation in such scenarios tends to break down into stages that include revision and proofreading – not only of language use, but of documentary form. What’s more, a phrase like “starred questions” and its correlating translation is a “top-down” linguistic phenomenon, designed, imposed, regularized, and consciously learned and implemented – not by speakers of a given language – but by institutions and institutional agents, including translators. From this perspective, the correlation IBM has discovered does not seem particularly relevant to “natural language” competence or innateness as discussed in the disputation, and highlights the conspicuous absence in the methodological debate of regard for the relationship between MT development and contexts and genres of use. Empiricist statistical modeling claimed to be finding deep correlations between languages in its mapping of the Hansard, and were skeptical of rationalist “toy” systems that limited themselves to specific translational and documentary niches because they couldn’t scale. The Canadian government’s MÉTÉO system, for example, which translated weather reports without human intervention, is a well-known example.32 Taken together, these examples suggest that if statistical modeling was going to improve, it needed something else, not only more data, but the recognition, already demonstrated by rationalist projects, of the specialized treatment of specific documentary genres.
Closing out the disputation with some summarizing statements, MT veteran Martin Kay noted the irony of how similar the rationalist and empiricist positions actually were, on the basis of the circumscribed problem spaces their hypotheses took into account. Just as the rationalist program was overly circumscribed in looking at language as evidence for language, the empiricist side, too, only looked at half the translation job. To work, Kay contended that
your empiricism would have to spread over a wider range of facts, such as, for example, how people react to texts of this sort, how they interpret them, under what sorts of circumstances they’re appropriate, and so on.
Although the statistical method showed undeniable promise, there was no evidence that they “worked” for MT, as Mercer had proposed in his keynote. Instead, the oppositional rhetoric helped sustain a theoretical controversy over the nature(s) of language and language data, rather than focus on the ways translation was actually practiced and translations (documents) produced and used. In fact, a hint of the connection between rule-making and outcomes was given at the outset of the disputation – a blast from Margaret King’s referee whistle would demand silence if things got too medieval, but it also regulated the speed of English-French interpreting provided for the meeting:
There’s been a supplementary request from the interpreters that if anybody is speaking so fast that they can’t keep up with the interpretation, the referee’s whistle will blow again. And in that case, it means “please slow down.”
At the risk of unduly conflating interpreting with translating, this tip of the hat to the difficulty of “processing” cross-lingual discussion on-the-fly is significant in an event dedicated to the automation of language transfer. The objective shared by everyone in the room was to reduce the time it took to translate. That a protocol was being introduced to manage the flow of debate in case it grew too noisy even for professionally trained interpreters to handle, might have reminded conference-goers that performance always followed rules of procedure. As the next section will demonstrate, this was something that the statistical machine method could not perfect without input from people, even though it would be deemed an operational success.
Good Applications for Crummy MT
While 1992 was a sea change year in MT methodology, shifts in approaches to MT evaluation were also underway, spurred by the growing commercial potential of MT. By no means had it been decided by that point that statistical methods would win out. In fact, DARPA had launched an MT initiative in late 1991 that funded three research teams (one was the IBM team), each of which used a different method, was applicable to a particular context for a particular purpose, and assumed a different level of involvement of people (writers, translators, readers, editors) in the translation workflow. Integral to the initiative was the development of an evaluations strategy that could compare the systems; this came to be called the “DARPA Methodology.”
In November 1992, a workshop called “MT Evaluation: Basis for Future Directions,” attended by many of the TMI-92 participants, showcased the DARPA evaluations approach.33 Before this time, evaluations had been done from scratch, in idiosyncratic – some said “crazy” – ways, by organizations making purchasing decisions, with results often kept confidential.34 Like TMI-92, this meeting aimed for a common path, “some kind of consensus about what counts as a reasonable way to do an evaluation and what counts as a valid basis for a judgment at the end of the day.”35
George Doddington, who headed the DARPA initiative, explained that their aim was to develop “revolutionary” MT technology.36 This would be “core MT technology,” understood as computer algorithms, not technology that integrated human translators at any stage of editing or composition. DARPA’s intention was to stimulate advances in AI and computers, so adopted a different orientation towards evaluation. While most researchers focused on assessments at “systems level,” asking how systems fared “in production translation use,” DARPA’s was “sort of a futuristic program,” whose core technology was developed “to support such systems in the future.” Simply stated, “the evaluation is intended to assess the core technology directly and not to evaluate the effectiveness of MT systems.”37
While that objective meant focusing on algorithms, it did not insist that the algorithms created would “work” on their own, but that they would power systems to which people would be integrated at some future date. Such a project, furthermore, could not be advanced if people (translators) remained part of the evaluation process, because they set the current performance bar too high. Algorithms needed to be assessed on their own terms, Doddington proposed, since they represented “the high-risk factor” determining how they’d get “from here to there,” as opposed to other innovation questions – such as the development of translator workstations, translation memories and terminological tools – which carried far less strategic risk.38
The DARPA evaluation strategy thus prioritized the development of future technology. Pliant, if not obfuscatory, phrasing helped Doddington simultaneously promote and undermine evaluation: he listed as a primary requirement “a cost-effective evaluation methodology that does not cripple the R&D effort by directing most of the effort toward evaluating technology rather than developing it.”39 In other words, an effective evaluation procedure would promote building technology in support of unstated (universal) future uses, rather than assess its performance or gauge its value with respect to current industry or professional needs. This is the crucial question. Does translation come into being as a technique, a procedure, or even an occurrence, without a context of use or application? It seems easier to argue that language learning can happen without context, even for a computer – think of the most common iterations of the Turing Test – but is there such thing as translation in potentia?
Human factors, furthermore, made human-centered evaluations unreliable. They were subjective and intuitive, and risked providing measures of human performance, instead of shining a light on the technology’s advancements. The difference with MT was that translation evaluation appeared to be subjectively ad hoc, answering only the fuzzy criterion-question: “Is this okay or not?”40 As Doddington put it, “putting a human in the loop tends to dull sensitivity to the MT algorithms.”41 The hunch had to be that technological improvements would bring gains once humans were re-inserted in the loop. Such predictions were easier to make when they were general and aimed at broad applicability at some point in the future, as Doddington claimed: “I believe judgments of quality or adequacy of fully automated MT will strongly correlate with the effectiveness of the algorithm in general for a variety of applications.”42
The line Doddington had drawn between “core technology” and systems for “production translation,” however, makes the claim hard to swallow. What, exactly, should one understand as “fully automated MT” here, as distinct from “the algorithm,” if computer algorithms were the core technology? The implication was that statistical MT presumed human editors and writers – they were integral to the concept of full automation – from the beginning of statistical MT, and instrumental in the vanquishing of the rationalist method. DARPA contributor John White alluded to the emerging new group of users qua operators, with reference to “people who you might expect would be users of this system sometime down the road.”43 Since assessment techniques needed to emphasize the technology itself, rather than translation as practiced according to professional standards already in place, the agents of such standards would be circumvented. Users “down the road” would be “novice people who were familiar with the two languages but were not professional translators.”44 Full automation would be achieved by looping future non-translators into an algorithmic translation process of a particular design.
The relationship between evaluation protocols as a key to development success becomes clearer when we discover an essay called “Good Applications for Crummy Machine Translation,” originally a talk at a Natural Language Processing evaluation workshop in 1991.45 One problem identified with implementing evaluation standards was that they “are not created or defined by decree but must evolve and earn community acceptance over time.”46 While the workshop was concerned with evaluation standards as applied within the MT and NLP development community, the translation industry had evolved its own community standards – not only as stylistic “norms,” but with respect to professional degrees, certified documents, and so on. Was the success of translation by machine to be assessed in light of these standards, or different ones?
The “Good Applications” article, by Kenneth Church (one of the four medieval disputators) and Eduard Hovy (of ISI/USC), got a more public reading when it appeared in a 1993 issue of Machine Translation journal – the first in a new “Point of View” column that aimed to encourage “high-quality scientific polemic” through opinion essays and reader response. In contrast to the disputation, which attached a presumption of MT success and failure to the way translation was theorized through its programming approach, Church and Hovy made an explicit and contingent link between success, context of application, and evaluation method. “If the application is well chosen,” the authors pointed out, “it often becomes fairly clear how the system should be evaluated.” What’s more, the “evaluation is likely to make the system look good.”47 In short:
it becomes crucial to the success of an MT effort to identify a high-payoff niche application so that system will stand up well to the evaluation, even though the system might produce crummy translations.48
Since MT was starting to prove its commercial viability, it was critical that evaluation standards contributed to, not hindered, its advance. That outcome could be avoided by seeking evaluation measures and applications that emphasized the value of MT research. While this was a pragmatic recommendation and an argument for realistic innovation goals, it must also be seen as radical shift away from general arguments made as to whether MT “worked” or not on the basis of concept and method. After all, this economic promise was already being achieved with rule-based systems with pre- and post-editing done by people; in contrast to something like MÉTÉO, this was not strictly speaking MT, but “machine aided” translation.
What’s more, despite the fact that people – editors, proofreaders, novice translators – were already part and parcel of these systems, evaluation would continue to hinge on distinguishing human from machine. “In order to design and build a theoretically and practically productive MAT system,” Church and Hovy suggested, “one must choose an application that exploits the strengths of the machine and does not compete with that of the human.”49 Citing industry colleagues, the authors implied further that operability was no longer in question, but simply a matter of domain – “The question now is not whether MT (or AI, for that matter) is feasible, but in what domains it is most likely to be effective.”50 Even though this success was already contingent on personnel, it looked likely that industry researchers would let the more general label ride – here MT, there AI – even when they were directed towards strategically selected niche functionalities.
It’s a subtle point, to be sure, but there does seem to an incongruence involved in maintaining the generalized term “MT” for a technology whose successful assessment relies on the introduction of highly task-dependent evaluation metrics. Church and Hovy, in fact, refer to an evaluation review that compared the extremely domain-restricted, yet near fully automatic MÉTÉO system, and a more open-task METAL system, to argue that metrics gave false comparative impressions, and failed to highlight the strengths of individual systems; it was the “desire for generality” that was to blame. While development should continue to seek generality in the operation of systems – task independence meant systems would scale, unlike MÉTÉO – metrics were needed that were “sensitive to the intended use of the system.”51
MT with post-editing had also proven disadvantageous from a cost-benefit standpoint, being more expensive than professional translation. Rather than finding niches for “fully automatic” MT, however, the authors took the now-familiar path of disruption, concluding that “it may not be commercially viable to use professional translators as post-editors.” Church and Hovy concentrated their recommendations on three ways forward. The first route, appealing to professional translators with a workstation, “uses the benefits of office-automation as a way to sneak technology into the translator’s workplace.”52 After outlining merits for translators, the remainder of the essay focused on how to circumvent these professionals in order to get MT output in front of end-users, a niche audience that wasn’t hung up on high quality.
Research had also shown, that is, that certain users would “opt for crummy quick-and-dirty translation, if they were given a choice.”53 They continued:
The trick to being able to capitalize on the speed of raw MT is to persuade both the translators and the end-users to accept lower quality. Apparently, the end-users are more easily convinced than the translators, and therefore, for this approach to fly, it is important that the end-users be in the position to choose between speed and quality.54
Realizing that end-users were not proficient in the languages in which they hoped to read or receive information, Church and Hovy imagined supplementing services such as email with a “Cliff-note mode” that would gloss words with equivalents. Like the improvements to the translator workstation, this enhancement was also a stealth move, “used as a way to sneak technology into the email reader.”55 The original focus on evaluating MT systems was thus replaced by a series of “modest attempts to appeal to the end-user.” “At first,” they wrote, “Cliff-note mode would do little more than table lookup, but a time goes on, it might begin to look more and more like machine translation.”56 Though Church and Hovy meant that the software would change (that is, improve), another reading is possible, whereby the human-machine amalgam “looks more like MT” as its users grow accustomed to the software as it has been presented to them, and take on translator-like interpretive skills to complete and perfect its function.
The Training Wheel
Although this period of MT history has always been framed as the success of statistical methods, what gets left out is the simultaneous expectation of incremental training by end-users to work with “raw” or “crummy” output. Such interactions could be considered evaluative in the sense that they trained end-users to regard even obvious drawbacks of the technology positively: “it is so simple that users shouldn’t have any trouble appreciating both the strengths as well as the weaknesses of the word-for-word approach.”57 An added outcome of smuggling in technology, however, was to make users the target of development. Cliff-note mode supplied a kind of “training-wheels” for language teaching that started out glossing words, then scaled back as the user’s French improved. Astoundingly, given the initial exhortation to circumvent the experts, they concluded by surmising that “Eventually, the user might become a professional translator.”58 With end-users becoming pro translators as “crummy MT” was made to be commercially viable, developers could have their cake and eat it, too. Indeed, as Church and Hovy put it, “the strategy of gradually introducing more and more technology is ideally suited for advancing the field toward desirable long-term goals.”59 And, with a prescient, now-familiar nod to the disruption-adverse, they added, “those who don’t like it, don’t have to use it.”60
While the evaluation discussions followed other paths as well, they showed a stark contrast with the arguments presented in the disputation, which imagined computability of translation as an independent, natural outcome of generalized language competence, whether located in an individual subject-mind, or consisting of transferable correlations discovered in a mass of text. With uncertainty a function of cost, however, they were already designing with people in mind. New assessment parameters that compared machines to machines, instead of machines to people, would not only create a new market for translation that rerouted around professional translators, but inscribe a corps of inexpert end-users in translation workflows themselves. Certainly other factors – corporate status, government support, the priority of scale, the benefit of time – helped boost statistical MT and push “toy” methods and narrower priorities to the sidelines. At the same time, this momentum was – and likely is still – supported by a key paradox or confusion about translation: whether it was primarily a matter of language acquisition – a competence, often decontextualized, and thus replicable by machines – or a context-determined document processing routine, maintained by social and technical apparatuses and protocols.
Translation theorists and historians have endeavoured to show that translation has always been a material, sociotechnical process that interacts with broader processes, for instance, of migration, printing, and globalization. See, for instance, Michael Cronin, Translation in the Digital Age (New York: Routledge), 2012; Anthony Pym, The Moving Text: localization, translation, and distribution (Amsterdam: John Benjamins), 2004; Lydia H. Liu, Tokens of exchange: the problem of translation in global circulations (Durham, NC: Duke University Press), 1999; Emily Apter, The Translation Zone (Cambridge: Princeton University Press), 2005; Michael Gordin, Scientific Babel: how science was done before and after global English (Chicago: University of Chicago Press), 2015. ↩
See Andrew Russell and Lee Vinsel, “Let’s Get Excited About Maintenance!” The New York Times, July 23, SR5. ↩
Such as Greg Downey’s on closed captioning, Leah Price and Pamela Thurschwell’s on literary secretaries, Scott Kushner’s on freelance translation as algorithmic piecework, and Sarah T. Roberts on web content moderation. See Gregory J Downey, Closed Captioning Subtitling, Stenography, and the Digital Convergence of Text with Television (Baltimore: Johns Hopkins University Press), 2008; Leah Price and Pamela Thurschwell, Literary Secretaries/Secretarial Culture (Aldershot: Ashgate), 2005; Scott Kushner, “The freelance translation machine: Algorithmic culture and the invisible industry,” New Media & Society, 15(8): 1241-1258; Sarah T Roberts, “Commercial Content Moderation: Digital Laborers’ Dirty Work” (2016). Media Studies Publications. Paper 12.http://ir.lib.uwo.ca/commpub/12. ↩
While the quality of MT output is usually regarded as related to the type and quantity of errors it produces, it must be noted that the concepts of “legibility” and “naturalness” in translation in general (literary translation, usually, but not exclusively), have been shown to be normative impositions that regard language difference as a barrier, instead of an asset and opportunity, and are features that reinforce the invisibility of translators and their tasks. See Lawrence Venuti, The Translator’s Invisibility: A History of Translation (London and New York: Routledge), 1995. Scholars have observed the emergence of code-mixing techno-languages as pushing against normalizations and Babelian tropes; see, for instance, Apter, Translation Zone, 226. With regard to the assumptions bound up with machine translation technology, Raley has argued that “what is to be resisted is the insistence on immediate and basic legibility.” See Rita Raley, “Machine Translation and Global English,” The Yale Journal of Criticism 16(2) (2003): 295. ↩
A mandate that makes (or promises to make) every inscription and speech act accessible, “all the time,” “on demand,” wherever we are.” Rita Raley, “Algorithmic Translations,” CR: The New Centennial Review, 16.1, Spring 2016, 122. ↩
Peter F. Brown, John Cocke, Stephen A. Della Pietra, Vincent J. Della Pietra, Fredrick Jelinek, John D. Lafferty, Robert L. Mercer, and Paul S. Roossin, “A Statistical Approach to Machine Translation,” Computational Linguistics, 16(2), June 1990, 79-85. The IBM first team presented its method in 1988, at the COLING (computational linguistics) conference in Budapest. The resulting article, “A statistical approach to machine translation,” appeared in Computational Linguistics in 1990. ↩
Peter Brown, Vincent J. Della Pietra, Stephen A. Della Pietra, and Robert Mercer, “The Mathematics of Statistical Machine Translation: Parameter Estimation,” Computational Linguistics 19(2), 263-311. ↩
The bulk of the TMI-92 papers are available at http://www.mt-archive.info/90/TMI-1992-TOC.htm. The conference was organized by the Canadian Workplace Automation Research Center (CWARC), in collaboration with the Secretary of State of Canada, and was supported by various American and Canadian governmental agencies: the Canadian Department of Communications, the Canadian Department of the Secretary of State, the US Defense Advanced Projects Research Agency (DARPA), Bell Canada, the Association for Machine Translation in the Americas (AMTA), and the International Association for Machine Translation (IAMT). See John W. Hutchins, “TMI in Montreal, 25-27 June 1992,” in MT News International, Issue no.3, September 1992. ↩
The twist takes on an interesting angle now, twenty-five years later, as the debate has flip-flopped again, with the victor-empiricists of old acting as the orthodox practitioners of a stodgy linguistic science and the new generation of machine learning researchers storming in as brazen technologists who have respect only for the method and not for the context of application. For a recent flare-up in the computational linguistics community, with reference to MT, see Yoav Goldberg’s post, “An Adversarial Review of “Adversarial Generation of Natural Language,”” subtitled “Or, for fucks sake, DL people, leave language alone and stop saying you solve it” (https://medium.com/@yoav.goldberg/an-adversarial-review-of-adversarial-generation-of-natural-language-409ac3378bd7) and response from Fernando Pereira, VP and Engineering Fellow at Google, titled “A (computational) linguistic farce in three acts,” http://www.earningmyturns.org/2017/06/a-computational-linguistic-farce-in.html, as well as a commentary by Yann LeCun, https://www.facebook.com/yann.lecun/posts/10154498539442143. ↩
Brown et al, “The Mathematics of Statistical,” 265. ↩
The paper is no longer available. This précis is in John Hutchins, “TMI in Montreal, 25-27 June 1992,” in MT News International, Issue no. 3, September 1992. ↩
Hutchins, “TMI in Montreal.” ↩
Wilks published this keynote as Yorick Wilks, “Stone Soup and the French Room,” Current issues in computational linguistics: in honour of Don Walker, eds. Zampolli, A., N. Calzolari & M. Palmer (Linguistica Computazionale, vol. 9-10), Pisa, Dordrecht (1994): 585-595. ↩
Tony Whitecomb, “Statistical Methods Gaining Ground,” Language Industry Monitor 11, September-October 1992. http://www.mt-archive.info/90/LIM-1992-11-1.pdf ↩
Peter F. Brown, Stephen A. Della Pietra, Vincent J. Della Pietra, John D. Lafferty, Robert L. Mercer Analysis, “Analysis, statistical transfer, and synthesis in machine translation.” Fourth International Conference on Theoretical and Methodological Issues in Machine Translation of Natural Languages (Montréal, Canada: CCRIT-CWARC, 1992), 83-100. http://www.mt-archive.info/TMI-1992-Brown.pdf ↩
Brown et al, “Analysis, statistical transfer,” 88. ↩
Brown et al, “Analysis, statistical transfer,” 88. ↩
Brown et al, “Analysis, statistical transfer,” 88. ↩
Brown et al, “Analysis, statistical transfer,” 91. ↩
A computer needs to disambiguate similar strings for processing. That “may” is a modal verb in one context and “May” is a noun might be accounted for by a linguistic theory, but writing conventions also function as parsing “clues.” Capitalization isn’t always useful, however; consider May” in “May I give it to May in May?” ↩
all quotations from the medieval disputation are from my transcription of the digitized audio recording, provided to me by TMI-92 organizer Pierre Isabelle. ↩
Hirst, incidentally, is known to the Digital Humanities community in connection with his research on the relationship between Alzheimer’s and changes in vocabulary in Agatha Christie’s novel writing; See Ian Lancashire and Graeme Hirst, “Vocabulary Changes in Agatha Christie’s Mysteries as an Indication of Dementia: A Case Study. In 19th Annual Rotman Research Institute Conference, Cognitive Aging: Research and Practice, 2009, 8-10. ↩
The target in this case was certainly Chomsky’s innateness theory, which proposed that humans possessed a mechanism for acquiring language and were (unconsciously) equipped with linguistic knowledge, such as the rules, constraints and organizing principles that linguists set about elucidating. ↩
Frederick Jelinek, “The Dawn of Statistical ASR and MT,” Computational Linguistics, Vol. 35, Issue 4, December 2009, 483-494. ↩
IBM had acquired four years of it, 1974-1978, in machine-readable format. I have not been able to find evidence of the transfer of the corpus from Government of Canada departments (likely, the Translation Bureau or Office of the Queen’s Printer) to IBM. In a 2015 interview I conducted with Peter F. Brown and Robert Mercer, they recall the data having been acquired as reels of magnetic tape. ↩
Wilks, “Stone Soup,” 591. ↩
Brown et al, “The Mathematics of Statistical,” 289. ↩
Brown et al., “The Mathematics of Statistical,” 289. ↩
Brown et al., “The Mathematics of Statistical,” 289. ↩
Brown et al., “The Mathematics of Statistical,” 295. ↩
Transcribed verbatim speech was often interposed with written “Order Papers” (questions) and responses that formed part of the debate proceedings, along with Appendices and other documentation. ↩
In the late 1960s, the Canadian government set out to develop their own MT software for the express purpose of speeding up Hansard production itself. That task proved too formidable, but MT research undertaken at the University of Montreal (with federal government support) eventually resulted in a successful, niche MT system called MÉTÉO, designed exclusively to translate government issued weather reports. The system was in operation from the late 1970s until the early 2000s. Though narrow in scope, the system was fully automatic, and used a top-down, genre-sensitive approach. ↩
The program and proceedings are available at http://www.mt-archive.info/90/AMTA-1992-TOC.htm. ↩
Margaret King, “International Coordination: International Working Group on MT Evaluation.” In Muriel Vasconcellos (ed.), MT evaluation: basis for future directions. Proceedings of a workshop sponsored by the National Science Foundation, 2-3 November 1992, San Diego, CA (Washington, DC: Association for Machine Translation in the Americas, 1994), 4-7. http://www.mt-archive.info/90/AMTA-1992-King.pdf ↩
Emphasis added. King, “International Coordination.” While the DARPA methodology figured prominently at that meeting, King noted that an international committee had recently been organized to look at evaluation, and other initiatives were emerging, such as an Expert Advisory Groups for Language Engineering Standards (EAGLES), based in Europe. ↩
George Doddington, “Panel: The DARPA Methodology.” In Muriel Vasconcellos (ed.), MT Evaluation: Basis for Future Directions: Proceedings of a Workshop Sponsored by the National Science Foundation, 2–3 November 1992, San Diego, CA (Washington, DC: Association for Machine Translation in the Americas, 1994), 14. ↩
Doddington, “Panel: The DARPA Methodology,” 14. ↩
Doddington, “Panel: The DARPA Methodology,” 14. ↩
Doddington, “Panel: The DARPA Methodology,” 14. ↩
John White, “Panel: The DARPA Methodology.” In Muriel Vasconcellos (ed.), MT Evaluation: Basis for Future Directions: Proceedings of a Workshop Sponsored by the National Science Foundation, 2–3 November 1992, San Diego, CA (Washington, DC: Association for Machine Translation in the Americas, 1994), 15. ↩
Doddington, “Panel: The DARPA Methodology,” 14. ↩
Doddington, “Panel: The DARPA Methodology,” 14. ↩
White, “Panel: The DARPA Methodology,” 16. ↩
White, “Panel: The DARPA Methodology,” 16. ↩
The workshop, sponsored by Rome Laboratory, was held on June 18, 1991, in conjunction with the 29th Annual Meeting of the Association for Computational Linguistics (ACL) on 18 June 1991 at UC Berkeley, and the essay is included in the workshop proceedings. See Jeanette G. Neal and Sharon M. Walter (eds.), Proceedings of the 1991 Natural Language Processing Systems Evaluation Workshop, RL-TR-91-362, Final Technical Report (Calspan-UB Research Center), December 1991. ↩
Introduction, Jeanette G. Neal and Sharon M. Walter (eds.), Proceedings of the 1991 Natural Language Processing Systems Evaluation Workshop, RL-TR-91-362, Final Technical Report (Calspan-UB Research Center), December 1991, viii. ↩
Church and Hovy, “Good Applications,” 239. ↩
Church and Hovy, “Good Applications,” 241. ↩
Church and Hovy, “Good Applications,” 240. ↩
Church and Hovy, “Good Applications,” 240. ↩
Church and Hovy, “Good Applications,” 241. ↩
Church and Hovy, “Good Applications,” 253. ↩
Church and Hovy, “Good Applications,” 253. ↩
Church and Hovy, “Good Applications,” 253. ↩
Church and Hovy, “Good Applications,” 255. ↩
Church and Hovy, “Good Applications,” 255. ↩
Church and Hovy, “Good Applications,” 256. ↩
Church and Hovy, “Good Applications,” 255-256. ↩
Church and Hovy, “Good Applications,” 256. ↩
Church and Hovy, “Good Applications,” 256. ↩
Article: Creative Commons Attribution-Non Commercial 3.0 Unported License.